Presented at the TESOL Arabia Conference in Dubai, March 13, 2015
by Vance Stevens vancestev@gmail.com
This proposal was made when I was developing materials to teach English listening to pilot cadets at KBZAC in Al Ain UAE. One important aspect of their English language training is being able to communicate with ATC (air traffic control) towers. At KBZAC we use real ATC recordings, and it is useful to render these in text format so as to make exercises that will train the cadets to listen and respond to text-based prompts that will both hone and test their comprehension.
The pedagogical issue
Because our class sizes are large (apprx. 20 per class) we develop materials that students can access through their devices: laptops or iPads.
The big problem with such broadcasts is that they are difficult sometimes to understand. The interchanges are highly contextualized (though knowing the context helps with comprehension). It is tedious to transcribe them, so I looked to speech-to-text software to improve my workflow. This presentation explains what I have discovered so far.
Getting text from printed text
Of course there are many ways to get machine text from printed text. You can scan it to yourself and convert it from the pdf to word. You can scan it into an optical character program and get text from that, or convert its image to text using One Note in the Microsoft Office Suite. But I find these methods to be a bit messy. There could be a weak part of the scan that requires you to make a lot of adjustments in your word processor to correct the area that is not rendered correctly. Reading it into your computer can be a good way to get it into text quickly, plus you have the affordance of an audio recording if you think to make one at the same time.
Discrete speech recognition
I used to work in software development in speech recognition. There are essentially two kinds of speech recognition, discrete and continuous. The former is the kind you encounter in phone router systems where the machine might prompt, is this an emergency, yes or no. You might answer, “no, it’s not an emergency, i just want to …” and the SR engine picks out the word ‘no’ and acts accordingly. Or you can be sitting at your computer and say FILE, and the file pulldown activates. You can then say new, open, or any number of choices available at that point which the system is now ready to act on. This is the kind of SR I worked with. Our software, called Tracy Talk, the Mystery (Harashima, 1999) held dialogs with language learners and gave them prompts they could read from the screen. The SR engine acted on proximity to the expected responses and carried on with the dialog accordingly, so the users, in the role of private detective, had the impression of conversing with the characters in the mystery. The SR engine was robust and could be tweaked, so our conversation simulations worked fairly well.
Continuous speech recognition
At the time we were developing Tracy Talk, continuous speech recognition, which works on natural language input, was not well developed. Dragon Systems had the best tool available. It was not free and it had to be trained by the user. Users who bought the package and worked with it over time could get it to take dictation pretty well.
For anyone with an awareness of the state of continuous SR last century, the developments in the past 20 years are amazing. Nowadays you can speak text messages to Google Glass or into your cell phone, and with some clunky exceptions, you can almost send as-is (it works a lot better than auto-correct :-). You can download Dragon as a free app on iPad and speak to it with very good results.
Dragon on the iPad
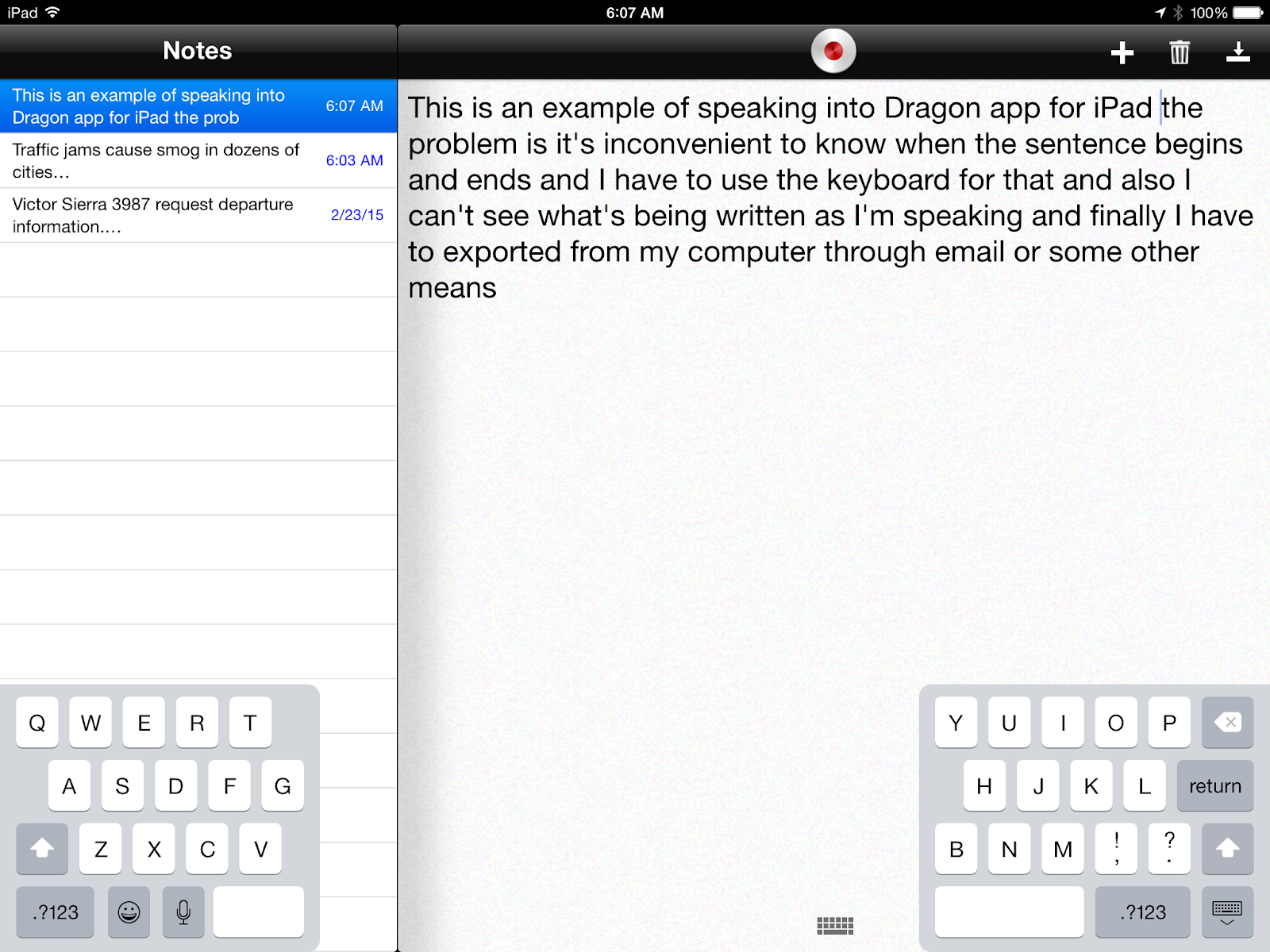
Dragon is the best software I’ve found on iPad for converting speech to text accurately and almost painlessly. I now use Dragon to create exercises where I read texts from our books and render soft copy from them that way. The problems I find with using Dragon on the iPad are (1) that it’s not seamless for me to correct the text, I can’t see the text as I’m recording it, and (2) having to export the text before I can use it.
First of all, making corrections to the text you have just recorded requires some dexterity with finger pointing and activating the keyboard exactly where you want it to appear in the text, especially if the text has gone to the bottom of the screen. I find it difficult but doable. This leads to the second problem, getting the text from the iPad into something I can work with. For me, real work requires a keyboard so I like to create exercises on my PC. To get from Dragon to a PC I use email, but of course I have to be connected if I want it right away; either that or I have to create multiple texts and leave them on my iPad and get them later when I am back online.
Text to speech on PC
The iPad is wonderful for having all you need, mic and apps, in a single device the size of a mousepad. But if you are willing to work from PC with a mic attached (I like USB mics best) then there are several tools you can use. One is http://speech-to-text-demo.mybluemix.net/ which allows you to speak into a mic on the left and renders the text on the right. You can copy what you get into whatever you are using to process text and work with that more seamlessly than if you start on iPad and end up on PC.
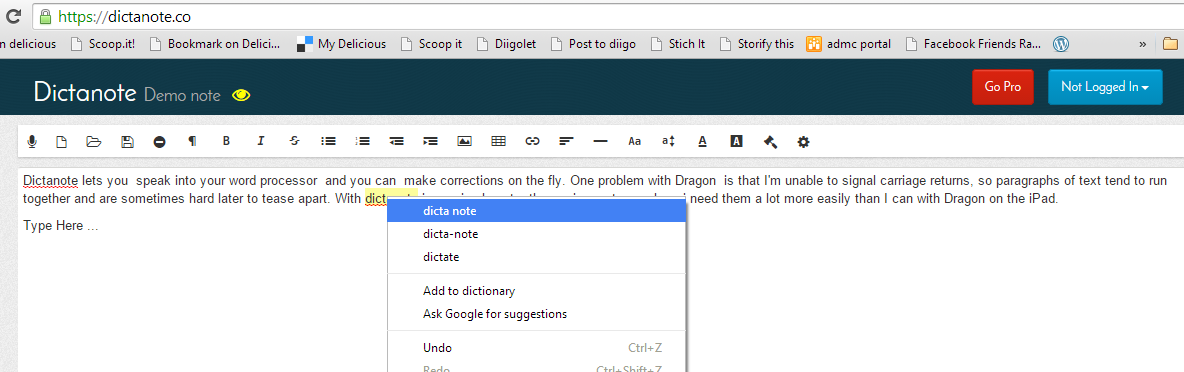
A tool I like even better is Dictanote, https://dictanote.co/, because it combines speech to text with the functionality of a notepad, which allows you to make corrections as you speak in a way that the other applications don’t. Dictanote lets you speak into your word processor and make corrections on the fly. A problem I had initially with Dragon was that I was unable to signal carriage returns, so paragraphs of text tended to run together and were hard later to tease apart. I have since found that if you keep handy a set of voice commands, you can invoke pronunciation; Google it or see for example http://isource.com/2009/12/09/some-tips-for-dragon-dictation/. The process is not intuitive, but with Dictanote i can simply join up text or enter the carriage returns on the fly where I need them a lot more easily than I can with Dragon on the iPad. There’s a full set of text processing tools available, even an autocorrect tool, though it doesn’t know when users are trying to say the name of the product :-). Still, you can do preliminary work right in Dictanote and copy your text from there into your word processor pretty much the way you want it.
Yet another advantage of using continuous SR engines is that while you are recording into them, you can create a simultaneous recording using Audacity. This is why I like to speak into Dragon on my iPad while recording that speech in Audacity on a PC via a USB mic. It makes good recordings for EFL learners because I speak distinctly for Dragon and if anything too slowly for Audacity, but it is an easy matter to go back into the recording to remove gaps and close up the utterances.
Pedagogical implications
Why would I want to do that? Suppose you want to have your students work from a text in their textbook. You can ask them to read it and do the exercises there and we all know that control over the class is hard to achieve when they are silently reading, or not. However, if you make an mp3 available to them, then play the mp3 as they follow the text, you can see they are on task, and they like the voice reinforcement. Then with the text you have rendered you can do some interesting things. You can find their vocabulary words in it, you can create text manipulation exercises, you can simply have it on the board and search it for things you want to point out to them in conjunction with exercises they may be doing.
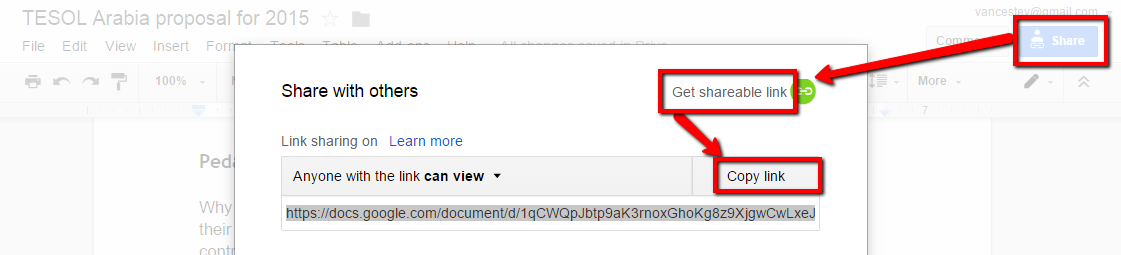
I find it most expedient to paste the texts I create in this way into Google Docs. I label the texts consistently; e.g. Unit 4 ‘texts’, IELTS 3 ‘texts’, and then I can search for ‘texts’ in my Drive and find all my texts created in this way. This way I can easily pull them up in class. I share them so that anyone with the link can VIEW the text, and I share that link with my students, so that they can search the texts on their own.
Getting text from unclear speech
But where the reading technique comes into its own is where there is no text to work from, where you want to get text from an audio recording, especially an unclear audio, such as our ATC broadcasts.
In our context, we can render the unclear audio to text by listening to it, parsing it mentally, saying it back into the SR engine, and then creating text manipulation exercises from it that force students to attend to certain details in the text / speech. We have created Hot Potatoes exercises where the audio is embedded in the exercise and the students can play the audio, complete the exercise, and get a score. In a Moodle context, HP will pass the scores to the LMS. In the Bb Learn environment we have not cracked this given limited time and resources available to us at KBZAC but we think it is possible (if you know how, please get in touch). In our context, I find that I can have students do the exercises in class and then call me over when done and let me record their scores from their screens. It’s a crude way to work but it is effective. It is the only way I have found to get a class of 20 cadets simultaneously on a listening task, each at his or her own pace, audibly and simultaneously engaged in listening and answering questions based on what I want them to listen to.
Making Hot Potatoes exercises with embedded audio
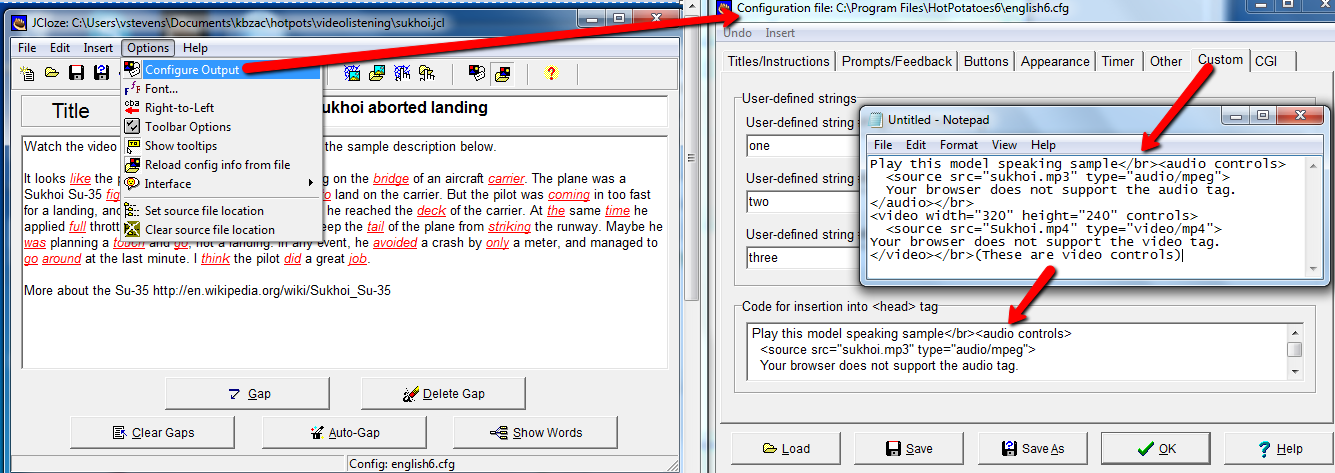
To make the HP exercises, you need to have your mp3 (or sometimes we use mp4) and then embed that into the HP module. The text rendered from speaking the text into an SR engine is then used to create the kind of exercise you wish to develop. The students can play the embedded video or audio at their own pace and complete and submit the exercise.
A Hot Potatoes exercise created in this way will have multiple files associated with it; at minimum the HP html file and its associated media file. The components of the exercise can be saved to a scorm package in HP which in effect places the parts needed into a folder which runs as a zip or rar file (zipping your files to a zip or rar packet is another way of doing the same thing, except that Bb Learn accepts scorm).
To Illustrate, we can use this HP exercise, which has both an mp3 and an mp4 embed
Sukhoi aborted carrier landing video and model speaking mp3 (voice: Vance)

The trick is to put some HTML into the Head of the HTML document that will play the files you place in the folder where the HTML file resides. Here the code looks like this:
Play this model speaking sample</br>
<audio controls>
<source src="sukhoi.mp3" type="audio/mpeg">
Your browser does not support the audio tag.
</audio></br>
<video width="320" height="240" controls>
<source src="Sukhoi.mp4" type="video/mp4">
Your browser does not support the video tag.
</video></br>
If you’re not too familiar with HTML (and this is HTML5) you can simply copy the code above and paste it where indicated in the dialog boxes shown below (for your HP exercise, of course, and where the mp3 and mp4 files have to be changed to the file names of the files you are using (to replace the file names shown in bold in the example above).
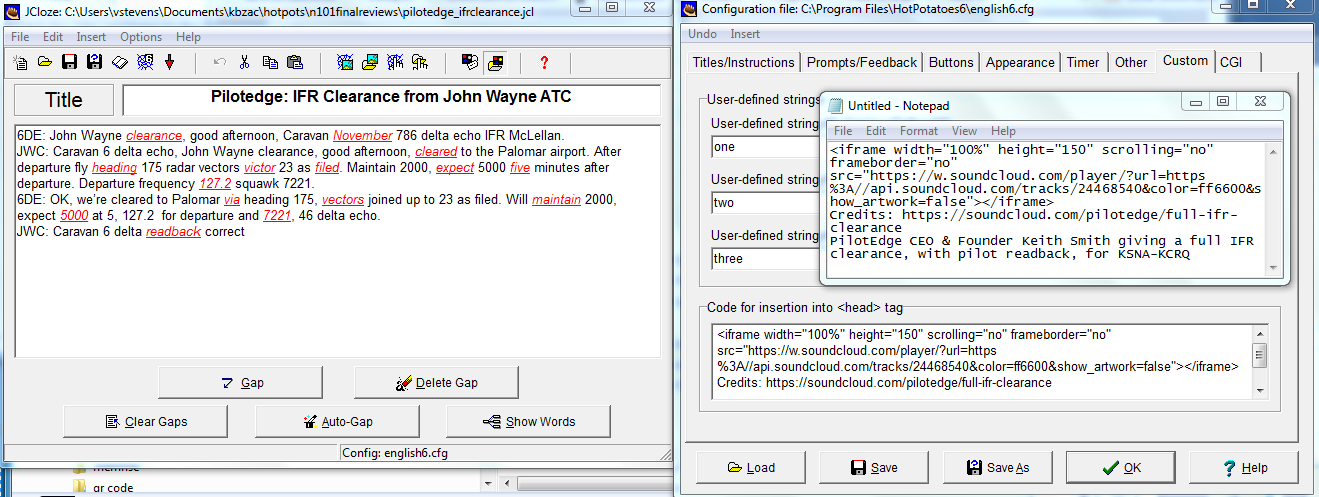
You can also embed a sound file from an online source, as in this example, from mp3s given as samples of a program that records pilot speech from John Wayne Airport simulations. You embed media from the Internet using the <iframe> tag.

Here is the code:
<iframe width="100%" height="150" scrolling="no" frameborder="no" src="https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/24468540&color=ff6600&show_artwork=false"></iframe>
Credits: https://soundcloud.com/pilotedge/full-ifr-clearance
PilotEdge CEO & Founder Keith Smith giving a full IFR clearance, with pilot readback, for KSNA-KCRQ
The credits are simply to acknowledge the source of the file on the Internet.
Here is where the embedded code is placed:
Getting Bb Learn to track student results from Hot Potatoes
In Nov 2014 we were actively pursuing getting these materials into Blackboard. At the time I gave a PD session to my colleagues where I work. The slide show from that presentation explains what we were able to find out about uploading the Scorm packages to Blackboard and getting the system to track the results. We didn’t reach our goal, but the slideshare explains the process we followed and how far we got:
http://www.slideshare.net/vances/listening-exercises4gradebook